 Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
In de vorige blog ben ik ingegaan op data science’s exploratory analysis en ik realiseerde me dat ik een trendy, maar erg handige techniek bij het onderzoeken van data vergeten ben te vermelden. Dat is namelijk: ‘Principal Component Analysis’ of ‘PCA’. Deze techniek is superhandig bij het analyseren van een grote set met ‘onduidelijke’ data. Laten we er eens wat verder in duiken….
Introductie van PCA, Principal Component Analysis
PCA is een methode die inzicht geeft in welke variabelen in een dataset de meeste verklarende waarde hebben. Het gebruikt techniek die zwaar leunt op lineaire algebra met veel gemanipuleer van matrices en vectoren.
Ik ga in deze blog geen uitleg geven over de achterliggende algebra, want dat zou te ver strekken en deze blogreeks is immers bedoeld voor managers en niet voor statistici. Dus ik zal mij na een korte beschrijving hieronder, beperken tot wat het doet en waar je het voor kunt gebruiken.
In essentie onderzoekt Principal Component Analysis de relatie tussen alle variabelen en alle observaties en geeft weer welke variabelen de grootste verklarende waarde hebben voor welke observaties. Hierbij gebruikt PCA onderliggend meestal ‘Singular Value Decomposition (SVD)’ en in sommige gevallen ‘Eigenvector Decomposition’. Beide technieken analyseren:
- De variantie: hoeveel varieert een variabel, dus in welke mate draagt hij bij aan de observatie en is daarmee het meest verklarend voor het gedrag van die observatie?
- De covariantie: hoe relateren (‘correleren’) de variabelen en observaties onderling? Anders gezegd: in welke mate beïnvloeden zij elkaar of in welke mate zijn zij onafhankelijk van elkaar?
Wat doet PCA?
Een dataset met metingen wordt door data scientists meestal omgevormd tot een matrix (een ‘dataframe’ of ‘tibble’). Dat betekent dat we er allerlei mooie matrixtechnieken op los kunnen laten. De techniek (SVD) haalt de originele dataset (in matrixvorm) uiteen in een drietal veelzeggende componenten. Zie afbeelding hieronder.
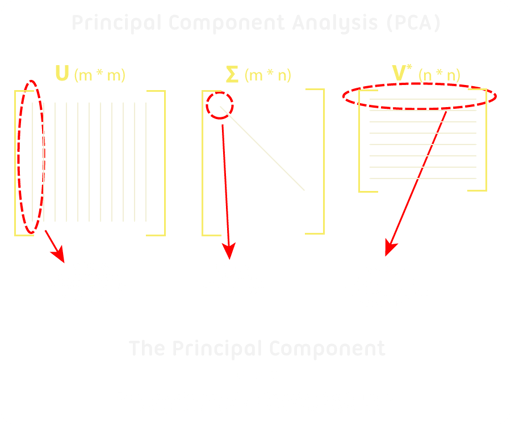
De middelste matrix geeft op de diagonaal van links naar rechts weer welke variabelen de meeste variantie vertonen en daarmee dus de meest verklarende waarde hebben. Voor managers lijkt het mij normaal gesproken voldoende om te weten dat er een goede techniek bestaat voor dit probleem. Als je toch meer over het SVD en PCA-proces wilt weten, verwijs ik graag naar een goede video in twee delen.
Wat doet PCA voor mij?
Stel je een matrix voor met prospect-data (bijvoorbeeld het gedrag en de eigenschappen van je prospect-database). En je bent op zoek naar welke eigenschappen bijvoorbeeld aankoopgedrag of churn beïnvloeden. Dan kun je met behulp van deze SVD/PCA-technieken de eigenschappen vaststellen die het meest verklarend zijn voor aankoop of churn.
PCA helpt hierbij zo goed, omdat het vrijwel nooit voorkomt dat alle eigenschappen van de prospects in je dataset onafhankelijk zijn. Daarom is het juist zo lastig om een goede uitspraak te doen over welke variabele of combinatie van variabelen er nu echt toe doet. Met behulp van PCA kun je dat veel beter doen. Je schoont als het ware je dataset op van onderling beïnvloedende variabelen en kijkt dan welke unieke set van eigenschappen gecombineerd met welke unieke set van gedrag het meest verklarend is.
Als je de best verklarende variabelen kunt aanwijzen tijdens je exploratory data analysis, dan kun je in de fasen daarop precies gaan vaststellen welk model dat verband het best weergeeft. Met die kennis kun je beter voorspellen welke prospects waarschijnlijk gaan aankopen en voor welke klanten je waarschijnlijk een retentie-aanpak moet bedenken. Daarmee kun je je NBA’s (Next Best Actions) beter bepalen of kun je target groups voor outbound campagnes beter selecteren.
Conclusie
De Data Scientist heeft een toolbox met technieken, die jou als manager met al je vragen vooruit kunnen helpen. SVD en PCA zijn voorbeelden van dat soort technieken. Je kunt er veel voorkomende vragen over data mee beantwoorden en ze maken dus vaak een vast onderdeel uit zijn van het DataScience proces.
Ben je nieuwsgierig wat de groei van Big Data en opkomst van Market Intelligence als een hulpmiddel betekenen voor jouw bedrijf? Op deze vraag zal in onderstaand E-book antwoord worden gegeven.

Laat hieronder een opmerking achter als je een bepaald onderwerp rond Marketing Intelligence wilt aandragen. Dan kan het zomaar voorkomen dat jouw situatie of vraag in een dedicated blog binnen de reeks wordt besproken.