 Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
Op onze vorige blog zijn veel vragen binnen gekomen over de mogelijke synergie tussen het Marketing Data Lake en het Marketing Data Warehouse. Begrijpelijk, want dat is een interessante vraag in het licht van dataconsistentie, kostenefficiëntie en toekomstvastheid. Daarom ben ik achter de tekentafel gaan zitten om een plaat te maken die de plekken van samenwerking tussen de ‘drukke, rumoerige’ research kant en de ‘rustig zoemende’ dataproductie kant weergeeft. Deze afbeelding wordt in deze blog nader toegelicht.
Data Science en Data Productie in samenhang
Hieronder staat een ontwerpschets van een BI-omgeving voor Marketing, met daarin de centrale positie van het Marketing Data Lake als voedingsbodem voor zowel Marketing Data Science als Marketing Data Warehousing.
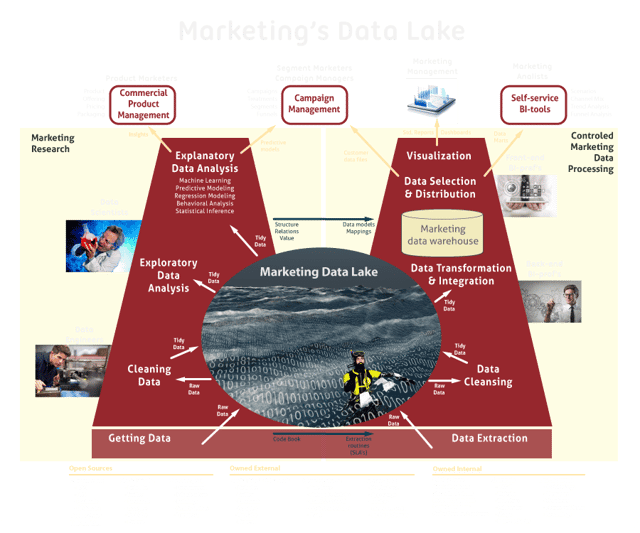
Databronnen voor het Marketing Data Lake
In de afbeelding heb ik een wat omvangrijker lijst van mogelijke databronnen opgenomen. Daarmee wil ik laten zien dat het tijdperk waarin alle managementinformatie uit standaard interne bronnen komt, wel zo’n beetje voorbij is. Het Data Lake is bij uitstek geschikt om allerlei data uit de meest uiteenlopende bronnen op te nemen. De variëteit van deze data neemt sterk toe door de steeds toenemende beschikbaarheid van open data, sensordata (IoT) en dark data. Dat laatste heeft betrekking op data die achter de schermen (bijvoorbeeld logs) in de interne systemen en in de infrastructuurtechniek (bijvoorbeeld messages en proces statussen) zijn ‘verborgen’. Als een soort interne sensor-data. Het is weliswaar meestal hoog-volume data, maar de tegenwoordige techniek maakt het makkelijker om deze te verwerken. Dark data bevat nu eenmaal veel basiswaarnemingen (vastgelegde events binnen de bedrijfprocessen) en heeft daardoor veel potentie als stuurinformatie.
Het Marketing Data Lake als centrale bron
Het data lake is gekoppeld met zowel de data science kant (marketing research) als de reguliere, geborgde data warehousing kant. Beide omgevingen voeden ruwe (raw) data en geschoonde (tidy) data in het data lake. Ook het reguliere marketing data warehouse wordt via ‘mappings’ (transformatie- en integratielogica) gevoed vanuit het lake. Dit werkt consistentie en synergie in de hand.
Samenhang tussen research en productie
Alle nieuw ontgonnen data zal eerst door de research kant heen lopen om te worden onderzocht op waarde. Hier wordt de betekenis van de data, de kwaliteit en de syntax duidelijk. De data engineer (of bij kleinere bedrijven; de data scientist zelf) zal de data ophalen, bekijken en opschonen (cleaning data). Als hij dit een beetje netjes doet, zal hij een code book opstellen waarin precies staat hoe hij de ruwe data ophaalt, interpreteert en bewerkt tot schone data.
De tidy data wordt door exploratory data analysis bekeken op potentiële waarde en relevantie voor Marketing. Dit geeft een soort eerste leidraad voor verder onderzoek. Explanatory data analysis – gericht op beantwoording van de onderzoeksvraag – is het hart van data science en bedoeld om de meest-verklarende variabelen te vinden. Daarmee kun je onder andere adequaat voorspellende modellen maken. Hiermee wil ik natuurlijk niet zeggen dat alle research altijd verklarend van aard is, we kennen immers bijvoorbeeld ook beschrijvend onderzoek.
Als uit het onderzoek blijkt dat de data inderdaad een hoge marketingwaarde heeft, is het mogelijk om deze data regulier op te nemen in de geborgde dataverwerking in het data warehouse. Het verklarend onderzoek heeft ons inmiddels voldoende begrip over de data gegeven in de vorm van syntax, semantiek, relaties en structuren. Deze informatie uit het onderzoek, kan door de ontwikkelaars van de reguliere data warehouse tak worden gebruikt om:
- de informatie op het dashboard of rapport in begrijpelijke vorm te tonen
- de datamodellering uit te voeren voor het data warehouse
- de mappings te maken om van tidy data, via het data warehouse, betekenisvolle informatie op de dashboards of in de data marts te kunnen genereren
- de extractie en cleansing van de ruwe data in nette productieprocedures te kunnen vormgeven (op basis van het code book)
De rollen rond het Marketing Data Lake en Warehouse
Bij non-multinationals (zeg MKB en National Enterprises) zal al het werk voor data science door de Data Scientist worden uitgevoerd. Hij is getraind om data uit bronnen te halen en op te schonen. Bij multinationals zien we tegenwoordig echter steeds meer een splitsing tussen getting & cleaning data en de onderzoeksmatige data-analyse zelf. Het eerste wordt dan opgepakt door een gespecialiseerde data engineer en het tweede door de data scientist. De data engineer lijkt ook steeds meer de geëigende term voor de back-end BI-professional binnen de data warehouse omgeving. Het is functioneel gelijk werk, alleen de tools en databases kunnen wat verschillen. Het feit dat het Data Lake alleen niet-geïntegreerde data bevat, maakt het leven van de professionele data engineer er alleen maar makkelijker op, omdat hij bij het vullen van het data lake (nog) geen gegevens hoeft te integreren.
Als het zover is dat de data engineer voor het onderzoek ook de integratie van gegevens in een samenhangend datamodel moet gaan doen, dan zijn de functies vergelijkbaar en zullen de termen in elkaar overgaan. Zoals wellicht bekend is de plek van data integratie het belangrijkste onderscheid tussen data science en data warehousing:
- Voor data warehousing geldt de volgorde: 1. extraction, 2. cleansing, 3. transformation/integration, en 4. storing. Dit heet in vaktermen ‘ETL’ (Extraction, Transformation, Loading) of ‘schema on write’ (we integreren de data in een model vóórdat we het wegschrijven in de database).
- Voor data science (of big data) geldt de volgorde: 1. getting, 2. cleaning, 3. storing en daarna pas 4. transformation/integration. Dit heet ‘ELT’ (Extraction, Loading, Transformation) of ‘schema on read’ (we gaan de data pas integreren als we de data gaan gebruiken, dus de opslag zelf - het data lake - bevat nog niet-geïntegreerde data).
De data scientist heeft – op basis van zijn onderzoeksvraag – ook allerlei data nodig die hij zelfstandig uit het data lake haalt. Zijn de benodigde data nog niet aanwezig dan stopt hij die er zelf in - eventueel met hulp van de data engineer.
De front-end BI-professional maakt management dashboards en reports, gebaseerd op de behoeften van de managers. Nieuwe data die binnenkomt vanuit marketingonderzoek (de data science kant) is altijd een antwoord op een onderzoeksvraag. De plaatjes die daarbij horen (meestal plots) zijn bedoeld om het antwoord inzichtelijk te maken. Als blijkt dat dat antwoord een continu karakter heeft (als je bijvoorbeeld de trend in de gaten wil blijven houden) dan kan een dergelijke visualisatie (plot) goed hergebruikt worden in een management dashboard. Ook hier werken de resultaten uit het voorafgaande onderzoek als mooie input voor de front-end BI-professional.
Conclusie
Er is veel samenhang en synergie te bereiken door de koppeling van data science en big data met data warehousing, waarbij het marketing data lake een centrale voedingsbodem kan zijn voor beide takken van sport. Ook is het zo dat de resultaten van een onderzoek in de marketing research kant vaak goed gebruikt kunnen worden bij de ontwikkeling en borging van de MI-levering in de data warehouse kant. Het is te verwachten dat deze omgevingen dichter naar elkaar toe kruipen en dat ook de rollen van de betrokken professionals gaan overlappen. Waar je je ook bevindt in de groeifasen van Marketing Intelligence; een plekje reserveren voor je Marketing Data Lake kan dus geen kwaad.
Wil je weten wat de groei van Big Data en de opkomst van Marketing Intelligence als hulpmiddel betekenen voor uw bedrijf? Onderstaand eBook is een verzamelijk van blogs geschreven door Gerrit Versteeg en geeft antwoord op onder andere bovenstaande vragen.

Laat hieronder een opmerking achter als je een bepaald onderwerp rond Marketing Intelligence wilt aandragen. Dan kan het zomaar voorkomen dat jouw situatie of vraag in een dedicated blog binnen de reeks wordt besproken.